Journals > > Topics > Machine Vision
Machine Vision|433 Article(s)

Influence of Imaging Parameters on Shape from Focus of Large-Depth Objects
Xiaohua Xia, Yusong Cao, Haoming Xiang, Shuhao Yuan, and Zhaokai Ge
ObjectiveShape from focus is a passive three-dimensional reconstruction technology that restores three-dimensional topography from multi-focused image sequences of target objects. To improve the reconstruction accuracy of this technology in practical applications, the existing methods mostly remove image jitter noise, improve focus measure operator and evaluation window, and optimize data interpolation or fitting algorithms. Although these methods can improve the accuracy of shape from focus, the influence of imaging parameters on reconstruction accuracy is not considered, and the accuracy of shape from focus should be further improved. We explore the influence of imaging parameters on the accuracy of shape from focus of large-depth objects and then clarify the improvement measures of the imaging system when the reconstructive accuracy of shape from focus does not meet the requirements in practical applications. Finally, our study helps select imaging parameters in the application of shape from focus technology to obtain better reconstruction accuracy.MethodsBased on constructing the evaluation index of 3D reconstruction accuracy of shape from focus, we firstly analyze the influence degree of focal length, F-number, pixel size, and other parameters in the imaging system on the accuracy of shape from focus by the equal-level orthogonal experiment of a single index. Meanwhile, the primary and secondary orders of the influence of these imaging parameters on the accuracy of shape from focus are determined. Then, the influence of main and sub-main imaging parameters on the 3D reconstruction accuracy is analyzed emphatically by experiments, and the relationship between the optimal imaging parameters and the sampling interval of multi-focus images is revealed. Finally, considering that the change of imaging parameters affects the restoration accuracy of shape from focus by changing the depth of field of the system, it is necessary to explore the influence of imaging parameters on the restoration accuracy of shape from focus of large-depth objects via the depth of field. The experiments help establish the empirical formula between the sampling interval of multi-focus images and the optimal depth of field, providing a theoretical basis for setting imaging parameters of the system.Results and DiscussionsAccording to the orthogonal experiment results (Table 3), focal length and F-number are the main and sub-main parameters affecting the accuracy of shape from focus, the influence of pixel size is less than focal length and F-number, and the influence of blank column is the least, which means that there are no important parameters that have not been analyzed. In practical applications, adjusting the focal length and F-number can be realized by adjusting the zoom lens with variable apertures, and meanwhile adjusting the pixel size usually requires replacing the camera, which is costly and usually not considered. Thus, the pixel size is regarded as a non-main influencing parameter. Analyzing the influence of main and sub-main parameters on the accuracy of shape from focus shows that there is the best focal length (Table 4) and the best F-number (Table 5) for the highest reconstruction accuracy under a given multi-focus image sampling interval, and with the decreasing sampling interval, the best focal length increases (Fig. 3) and the best F-number reduces (Fig. 4). Considering that the change of imaging parameters affects the accuracy of shape from focus by changing the depth of field of the system, we establish an empirical formula between the sampling interval of multi-focus images and the optimal depth of field. The fitting accuracy of the empirical formula is 97.28% (Table 6), and the verification accuracy is 94.76% (Table 7), which can be adopted to calculate the optimal depth of field. The optimal depth of field can significantly improve the accuracy of shape from focus (Table 9), which provides a new way for improving the accuracy of shape from focus of large-depth objects.ConclusionsThe primary and secondary orders of the influence of imaging parameters on the accuracy of shape from the focus of large-depth objects are discovered, including focal length, F-number, and pixel size. The influence of main and sub-main imaging parameters, focal length, and F-number is analyzed emphatically. It is known that the root mean square error of object reconstruction results decreases first and then increases with the rising focal length or F-number in a given multi-focus image sampling interval, and there is an optimal focal length and F-number that leads to the highest reconstruction accuracy. With the decreasing sampling interval, the optimal focal length increases and the optimal F-number reduces. We consider that the change of imaging parameters affects the accuracy of shape from focus by changing the depth of field of the system. The experiments indicate that the empirical formula between the optimal depth of field and the sampling interval of multi-focused images is obtained. The accuracy of the empirical formula obtained by the verified data is 94.76%, which can be employed to calculate the optimal depth of field. Our experiments show that adjusting the focal length and F-number of the imaging system according to the optimal depth of field can significantly improve the 3D reconstruction accuracy of large-depth objects. ObjectiveShape from focus is a passive three-dimensional reconstruction technology that restores three-dimensional topography from multi-focused image sequences of target objects. To improve the reconstruction accuracy of this technology in practical applications, the existing methods mostly remove image jitter noise, improve focus measure operator and evaluation window, and optimize data interpolation or fitting algorithms. Although these methods can improve the accuracy of shape from focus, the influence of imaging parameters on reconstruction accuracy is not considered, and the accuracy of shape from focus should be further improved. We explore the influence of imaging parameters on the accuracy of shape from focus of large-depth objects and then clarify the improvement measures of the imaging system when the reconstructive accuracy of shape from focus does not meet the requirements in practical applications. Finally, our study helps select imaging parameters in the application of shape from focus technology to obtain better reconstruction accuracy.MethodsBased on constructing the evaluation index of 3D reconstruction accuracy of shape from focus, we firstly analyze the influence degree of focal length, F-number, pixel size, and other parameters in the imaging system on the accuracy of shape from focus by the equal-level orthogonal experiment of a single index. Meanwhile, the primary and secondary orders of the influence of these imaging parameters on the accuracy of shape from focus are determined. Then, the influence of main and sub-main imaging parameters on the 3D reconstruction accuracy is analyzed emphatically by experiments, and the relationship between the optimal imaging parameters and the sampling interval of multi-focus images is revealed. Finally, considering that the change of imaging parameters affects the restoration accuracy of shape from focus by changing the depth of field of the system, it is necessary to explore the influence of imaging parameters on the restoration accuracy of shape from focus of large-depth objects via the depth of field. The experiments help establish the empirical formula between the sampling interval of multi-focus images and the optimal depth of field, providing a theoretical basis for setting imaging parameters of the system.Results and DiscussionsAccording to the orthogonal experiment results (Table 3), focal length and F-number are the main and sub-main parameters affecting the accuracy of shape from focus, the influence of pixel size is less than focal length and F-number, and the influence of blank column is the least, which means that there are no important parameters that have not been analyzed. In practical applications, adjusting the focal length and F-number can be realized by adjusting the zoom lens with variable apertures, and meanwhile adjusting the pixel size usually requires replacing the camera, which is costly and usually not considered. Thus, the pixel size is regarded as a non-main influencing parameter. Analyzing the influence of main and sub-main parameters on the accuracy of shape from focus shows that there is the best focal length (Table 4) and the best F-number (Table 5) for the highest reconstruction accuracy under a given multi-focus image sampling interval, and with the decreasing sampling interval, the best focal length increases (Fig. 3) and the best F-number reduces (Fig. 4). Considering that the change of imaging parameters affects the accuracy of shape from focus by changing the depth of field of the system, we establish an empirical formula between the sampling interval of multi-focus images and the optimal depth of field. The fitting accuracy of the empirical formula is 97.28% (Table 6), and the verification accuracy is 94.76% (Table 7), which can be adopted to calculate the optimal depth of field. The optimal depth of field can significantly improve the accuracy of shape from focus (Table 9), which provides a new way for improving the accuracy of shape from focus of large-depth objects.ConclusionsThe primary and secondary orders of the influence of imaging parameters on the accuracy of shape from the focus of large-depth objects are discovered, including focal length, F-number, and pixel size. The influence of main and sub-main imaging parameters, focal length, and F-number is analyzed emphatically. It is known that the root mean square error of object reconstruction results decreases first and then increases with the rising focal length or F-number in a given multi-focus image sampling interval, and there is an optimal focal length and F-number that leads to the highest reconstruction accuracy. With the decreasing sampling interval, the optimal focal length increases and the optimal F-number reduces. We consider that the change of imaging parameters affects the accuracy of shape from focus by changing the depth of field of the system. The experiments indicate that the empirical formula between the optimal depth of field and the sampling interval of multi-focused images is obtained. The accuracy of the empirical formula obtained by the verified data is 94.76%, which can be employed to calculate the optimal depth of field. Our experiments show that adjusting the focal length and F-number of the imaging system according to the optimal depth of field can significantly improve the 3D reconstruction accuracy of large-depth objects.
Acta Optica Sinica
- Publication Date: Apr. 25, 2024
- Vol. 44, Issue 8, 0815001 (2024)

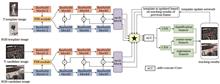
Cross-Modal Optical Information Interaction and Template Dynamic Update for RGBT Target Tracking Method
Jianming Chen, Dingjian Li, Xiangjin Zeng, Zhenbo Ren, Jianglei Di, and Yuwen Qin
ObjectiveRGB and thermal infrared (RGBT) tracking technology fully leverages the complementary advantages of different optical modalities, providing effective solutions for target tracking challenges in complex environments. However, the performance of many tracking algorithms is constrained due to the neglect of information exchange between modalities. Simultaneously, as the tracking template remains fixed, existing tracking methods based on Siamese networks face limitations in adapting to variations in target appearance, resulting in tracking drift. Therefore, enhancing the performance of target trackers in complex environments remains challenging.MethodsThe proposed algorithm adopts the Siamese network tracker as its foundational framework and introduces a feature interaction module to enhance inter-modal information exchange by reconstructing information proportions of different modalities. Based on the anchor-free concept, a prediction network is directly constructed to perform classification and regression on the target bounding box at each position point in the search region. To address the mismatch between the target and template during the tracking of the Siamese network tracker, we propose a template update strategy, which dynamically updates the tracking template using the predicted results from the previous frame.Results and DiscussionsQualitative and quantitative experiments are carried out on SiamCTU and advanced RGBT target tracking models, with ablation experiments analyzed. Meanwhile, comparative experiments are conducted by evaluating the proposed target tracker against state-of-the-art target trackers on three benchmark datasets (GTOT, RGBT234, and LasHeR) to assess the tracking performance of the algorithm. Figs. 6, 7, and 9 respectively display the quantitative comparison results between SiamCTU and advanced RGBT tracking algorithms on the three benchmark datasets. Compared with advanced RGBT target tracking algorithms, the experimental results on three baseline datasets demonstrate outstanding tracking performance of SiamCTU, fully exhibiting the effectiveness of the proposed method. Specifically, on the GTOT and LasHeR datasets, the proposed tracking algorithm secures top rankings in both PR and SR. Fig. 8 and Table 1 respectively present the experimental results based on challenge attributes for the tracking algorithm on the GTOT and RGBT234 datasets. The experimental results show that SiamCTU exhibits excellent tracking performance under various challenging attributes, suggesting that the proposed tracker is effective in handling complex target tracking scenarios. To provide a more intuitive demonstration of the tracker's tracking performance, we visualize the tracking results in Fig. 10. In the LightOcc sequence [Fig. 10(a)], the proposed tracking algorithm utilizing the template update strategy maintains continuous and stable tracking of the target even under such challenges as occlusion and low illumination. For scenarios involving significant scale variations [Fig. 10(b)], the proposed tracker outperforms the comparative tracker, demonstrating the advantages of constructing a prediction network based on the anchor-free concept. The visual results in Figs. 10(c) and 10(d) reveal that the proposed tracker can leverage the complementary advantages of RGB and T modalities, reducing interference from similar objects. Meanwhile, the comparative tracking efficiency analysis of the tracker on the GTOT dataset (Table 2) indicates that SiamCTU significantly improves tracking accuracy with minimal tracking speed loss. Furthermore, the proposed tracker exhibits higher speed and precision advantages over the advanced MDNet-based tracker. In further ablation experiments (Table 3), the performance of the proposed tracker surpasses that of the baseline tracker, which underscores the substantial contributions of various modules designed in the algorithm and collectively enhances the tracker's ability to handle complex tracking scenarios. Specifically, when the feature interaction module is removed, the overall performance of SiamCTU decreases by 3.1% on the more complex RGBT234 dataset. Additionally, by varying template update parameters to study their influence on tracking performance, experimental results (Table 4) indicate that with an appropriate value of λ as the update parameter, the feature-level template update method can significantly enhance the tracker's performance.ConclusionsTo address the target tracking challenges in complex environments, we propose a cross-modal optical information interaction method for RGBT target tracking. The tracking model adopts the Siamese network as its foundational framework and incorporates a feature interaction module. This module enhances the inter-modal information exchange by reconstructing information proportions of different optical modalities, mitigating the effect of complex backgrounds on tracking performance. Subsequently, by dealing with the relationship between the tracker's initial template and the online template, we introduce a template dynamic updating strategy. This strategy dynamically updates the tracking template using predicted results, capturing the real-time status of the target and improving the algorithm's robustness. Evaluation results on three benchmark datasets including GTOT, RGBT234, and LasHeR demonstrate that the proposed method surpasses current advanced RGBT target tracking methods in terms of tracking accuracy. Additionally, it meets real-time tracking requirements and holds potential for broad applications in optical information detection, perception, and recognition of targets in complex environments. ObjectiveRGB and thermal infrared (RGBT) tracking technology fully leverages the complementary advantages of different optical modalities, providing effective solutions for target tracking challenges in complex environments. However, the performance of many tracking algorithms is constrained due to the neglect of information exchange between modalities. Simultaneously, as the tracking template remains fixed, existing tracking methods based on Siamese networks face limitations in adapting to variations in target appearance, resulting in tracking drift. Therefore, enhancing the performance of target trackers in complex environments remains challenging.MethodsThe proposed algorithm adopts the Siamese network tracker as its foundational framework and introduces a feature interaction module to enhance inter-modal information exchange by reconstructing information proportions of different modalities. Based on the anchor-free concept, a prediction network is directly constructed to perform classification and regression on the target bounding box at each position point in the search region. To address the mismatch between the target and template during the tracking of the Siamese network tracker, we propose a template update strategy, which dynamically updates the tracking template using the predicted results from the previous frame.Results and DiscussionsQualitative and quantitative experiments are carried out on SiamCTU and advanced RGBT target tracking models, with ablation experiments analyzed. Meanwhile, comparative experiments are conducted by evaluating the proposed target tracker against state-of-the-art target trackers on three benchmark datasets (GTOT, RGBT234, and LasHeR) to assess the tracking performance of the algorithm. Figs. 6, 7, and 9 respectively display the quantitative comparison results between SiamCTU and advanced RGBT tracking algorithms on the three benchmark datasets. Compared with advanced RGBT target tracking algorithms, the experimental results on three baseline datasets demonstrate outstanding tracking performance of SiamCTU, fully exhibiting the effectiveness of the proposed method. Specifically, on the GTOT and LasHeR datasets, the proposed tracking algorithm secures top rankings in both PR and SR. Fig. 8 and Table 1 respectively present the experimental results based on challenge attributes for the tracking algorithm on the GTOT and RGBT234 datasets. The experimental results show that SiamCTU exhibits excellent tracking performance under various challenging attributes, suggesting that the proposed tracker is effective in handling complex target tracking scenarios. To provide a more intuitive demonstration of the tracker's tracking performance, we visualize the tracking results in Fig. 10. In the LightOcc sequence [Fig. 10(a)], the proposed tracking algorithm utilizing the template update strategy maintains continuous and stable tracking of the target even under such challenges as occlusion and low illumination. For scenarios involving significant scale variations [Fig. 10(b)], the proposed tracker outperforms the comparative tracker, demonstrating the advantages of constructing a prediction network based on the anchor-free concept. The visual results in Figs. 10(c) and 10(d) reveal that the proposed tracker can leverage the complementary advantages of RGB and T modalities, reducing interference from similar objects. Meanwhile, the comparative tracking efficiency analysis of the tracker on the GTOT dataset (Table 2) indicates that SiamCTU significantly improves tracking accuracy with minimal tracking speed loss. Furthermore, the proposed tracker exhibits higher speed and precision advantages over the advanced MDNet-based tracker. In further ablation experiments (Table 3), the performance of the proposed tracker surpasses that of the baseline tracker, which underscores the substantial contributions of various modules designed in the algorithm and collectively enhances the tracker's ability to handle complex tracking scenarios. Specifically, when the feature interaction module is removed, the overall performance of SiamCTU decreases by 3.1% on the more complex RGBT234 dataset. Additionally, by varying template update parameters to study their influence on tracking performance, experimental results (Table 4) indicate that with an appropriate value of λ as the update parameter, the feature-level template update method can significantly enhance the tracker's performance.ConclusionsTo address the target tracking challenges in complex environments, we propose a cross-modal optical information interaction method for RGBT target tracking. The tracking model adopts the Siamese network as its foundational framework and incorporates a feature interaction module. This module enhances the inter-modal information exchange by reconstructing information proportions of different optical modalities, mitigating the effect of complex backgrounds on tracking performance. Subsequently, by dealing with the relationship between the tracker's initial template and the online template, we introduce a template dynamic updating strategy. This strategy dynamically updates the tracking template using predicted results, capturing the real-time status of the target and improving the algorithm's robustness. Evaluation results on three benchmark datasets including GTOT, RGBT234, and LasHeR demonstrate that the proposed method surpasses current advanced RGBT target tracking methods in terms of tracking accuracy. Additionally, it meets real-time tracking requirements and holds potential for broad applications in optical information detection, perception, and recognition of targets in complex environments.
Acta Optica Sinica
- Publication Date: Apr. 10, 2024
- Vol. 44, Issue 7, 0715001 (2024)
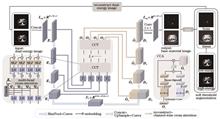
Dual-Energy CT Base Material Decomposition Method Based on Multi-Channel Cross-Convolution UCTransNet
Fan Wu, Tong Jin, Guorui Zhan, Jingjing Xie, Jin Liu, and Yikun Zhang
ObjectiveDual-energy computed tomography (DECT) is a medical imaging technology that provides richer tissue contrast and material decomposition capabilities by simultaneously acquiring X-ray absorption information at two different energy levels, and it is increasingly widely used. In DECT, based on the energy absorption differences of different materials, the scanning objects can be decomposed into different base material components, such as bone and soft tissue. However, accurate decomposition and reconstruction of base material images remain a challenging problem due to factors such as noise, artifacts, and overlap. Therefore, we aim to improve the quality and accuracy of base material decomposition in DECT imaging. Current base material decomposition methods may have some limitations in complex scenarios, such as the failure to accurately decompose overlapping materials, vulnerability to noise interference, and poor image quality. To solve these problems and improve the properties of base material decomposition, a new base material decomposition method is proposed in this study.MethodsWe aim to improve the quality and accuracy of base material decomposition in DECT images. To achieve this goal, we propose a method based on the multi-channel cross-convolutional UCTransNet (MC-UCTransNet), which is performed by fitting the mapping function in DECT. The network is designed to be a double-in-double-out architecture based on UCTransNet. During training, with the real decomposition image as labels, a pair of double energy images as input, and its concating into the form of multi-channel, our multi-channel network structure aims to realize the information exchange between two material generation paths in the network. The channel cross-fusion converter and channel cross-attention module are used to improve the decomposition of base materials, realizing double-input-double-output and end-to-end mapping. Further, the channel cross-fusion module and the channel cross-attention module can better capture the complex channel correlation to more fully conduct feature extraction and fusion and realize the information exchange between the generation paths of base materials. To improve the model fitting performance, the network is trained using a hybrid loss. Meanwhile, in order to better adapt to the particularity of CT image data, the model uses the normalization method based on the Sigmoid function to preprocess the network input data and improve the model fitting performance.Results and DiscussionsIn order to verify the decomposition accuracy of each method, we not only compare the base material images decomposed by various methods but also reconstruct the base material images to the low energy image, and we compare them with the original low energy image. By obtaining the difference map to intuitively feel the decomposition effect of each method, the experimental results show that the proposed method is able to obtain images of water and soft tissue. Compared with the contrast method, the decomposed images perform better in accuracy and noise contrast suppression. Meanwhile, the results of the ablation experiments also demonstrate the attention mechanism, the mixed loss, and the effectiveness of the Sigmoid normalization method in this task. The introduction of the attention mechanism enables the network to better capture the information of key features in the image and improves the accuracy of decomposition. The mixed loss function of mean absolute error (MAE) and structural similarity index measure (SSIM) is used to improve the network decomposition effect and performance. In addition, the application of the Sigmoid normalization method can better adapt to the particularity of CT image data. On the premise of maintaining the distribution characteristics of the data, the interference of abnormal data to the model can be reduced, and the stability and accuracy of the model can be improved. The loss and peak signal-to-noise ratio (PSNR) values of the proposed method are superior in both the training and validation sets, with fast convergence and good stability, as well as a good decomposition effect on different test sets, showing strong generalization ability. This indicates that the dual energy-based MC-UCTransNet method has high utility in the base material decomposition task of DECT imaging.ConclusionsWe aim to improve the quality and accuracy of base material decomposition in DECT, and remarkable progress is made by proposing a dual material decomposition method based on MC-UCTransNet. Our study innovatively adopts the MC-UCTransNet network to integrate multi-channel cross-convolution with cross-attention mechanism modules to better capture the correlation among complex channels and realize information exchange between generation pathways of base materials. Moreover, the multi-channel cross structure avoids the use of multi-network for high and low energy information extraction, which makes the network model more convenient. In addition, we further improve the fitting performance of the model by the use of mixed loss and normalization methods based on the Sigmoid function. The experimental results show that the proposed method can ensure a promising improvement in water bone-based material and soft tissue iodine-based material decomposition tasks. ObjectiveDual-energy computed tomography (DECT) is a medical imaging technology that provides richer tissue contrast and material decomposition capabilities by simultaneously acquiring X-ray absorption information at two different energy levels, and it is increasingly widely used. In DECT, based on the energy absorption differences of different materials, the scanning objects can be decomposed into different base material components, such as bone and soft tissue. However, accurate decomposition and reconstruction of base material images remain a challenging problem due to factors such as noise, artifacts, and overlap. Therefore, we aim to improve the quality and accuracy of base material decomposition in DECT imaging. Current base material decomposition methods may have some limitations in complex scenarios, such as the failure to accurately decompose overlapping materials, vulnerability to noise interference, and poor image quality. To solve these problems and improve the properties of base material decomposition, a new base material decomposition method is proposed in this study.MethodsWe aim to improve the quality and accuracy of base material decomposition in DECT images. To achieve this goal, we propose a method based on the multi-channel cross-convolutional UCTransNet (MC-UCTransNet), which is performed by fitting the mapping function in DECT. The network is designed to be a double-in-double-out architecture based on UCTransNet. During training, with the real decomposition image as labels, a pair of double energy images as input, and its concating into the form of multi-channel, our multi-channel network structure aims to realize the information exchange between two material generation paths in the network. The channel cross-fusion converter and channel cross-attention module are used to improve the decomposition of base materials, realizing double-input-double-output and end-to-end mapping. Further, the channel cross-fusion module and the channel cross-attention module can better capture the complex channel correlation to more fully conduct feature extraction and fusion and realize the information exchange between the generation paths of base materials. To improve the model fitting performance, the network is trained using a hybrid loss. Meanwhile, in order to better adapt to the particularity of CT image data, the model uses the normalization method based on the Sigmoid function to preprocess the network input data and improve the model fitting performance.Results and DiscussionsIn order to verify the decomposition accuracy of each method, we not only compare the base material images decomposed by various methods but also reconstruct the base material images to the low energy image, and we compare them with the original low energy image. By obtaining the difference map to intuitively feel the decomposition effect of each method, the experimental results show that the proposed method is able to obtain images of water and soft tissue. Compared with the contrast method, the decomposed images perform better in accuracy and noise contrast suppression. Meanwhile, the results of the ablation experiments also demonstrate the attention mechanism, the mixed loss, and the effectiveness of the Sigmoid normalization method in this task. The introduction of the attention mechanism enables the network to better capture the information of key features in the image and improves the accuracy of decomposition. The mixed loss function of mean absolute error (MAE) and structural similarity index measure (SSIM) is used to improve the network decomposition effect and performance. In addition, the application of the Sigmoid normalization method can better adapt to the particularity of CT image data. On the premise of maintaining the distribution characteristics of the data, the interference of abnormal data to the model can be reduced, and the stability and accuracy of the model can be improved. The loss and peak signal-to-noise ratio (PSNR) values of the proposed method are superior in both the training and validation sets, with fast convergence and good stability, as well as a good decomposition effect on different test sets, showing strong generalization ability. This indicates that the dual energy-based MC-UCTransNet method has high utility in the base material decomposition task of DECT imaging.ConclusionsWe aim to improve the quality and accuracy of base material decomposition in DECT, and remarkable progress is made by proposing a dual material decomposition method based on MC-UCTransNet. Our study innovatively adopts the MC-UCTransNet network to integrate multi-channel cross-convolution with cross-attention mechanism modules to better capture the correlation among complex channels and realize information exchange between generation pathways of base materials. Moreover, the multi-channel cross structure avoids the use of multi-network for high and low energy information extraction, which makes the network model more convenient. In addition, we further improve the fitting performance of the model by the use of mixed loss and normalization methods based on the Sigmoid function. The experimental results show that the proposed method can ensure a promising improvement in water bone-based material and soft tissue iodine-based material decomposition tasks.
Acta Optica Sinica
- Publication Date: Mar. 10, 2024
- Vol. 44, Issue 5, 0515001 (2024)
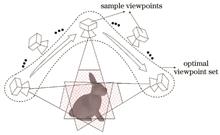
Multi-Objective Optimization-Based Planning Algorithm for Efficient Visual Inspection
Haihua Cui, Longfei Tian, Jiarui Wang, Junxue Qu, Feng Yang, and Jungang Guo
ObjectiveWith the increasing demand for inspecting part surfaces, automated and efficient visual inspection is becoming a trend in industrial production. Due to the complexity of inspection planning problems where both viewpoint planning and path planning belong to the non-determinism of polynomial complexity problem, most of the current research studies the above two problems separately and seeks the minimum viewpoints to satisfy the viewpoint coverage by viewpoint planning, then obtaining efficient inspection paths via path planning for the set of viewpoints. However, viewpoint planning and path planning are coupled problems, and the distribution of viewpoints and paths can easily make the inspection efficiency fall into the local optimum. Therefore, some researchers propose to combine the viewpoint and path planning problems and simplify them into a single objective problem for global optimization, which improves inspection efficiency to a certain extent. However, during the optimization, viewpoints should be continuously added to the viewpoint set to meet the viewpoint coverage, which causes low planning efficiency. To this end, we propose a multi-objective holistic planning method of viewpoints and paths to quickly seek the viewpoint set and its path that satisfy viewpoint coverage and optimal inspection time cost.MethodsIn response to the need for efficient inspection of batch parts, we study the inspection planning method of automated visual inspection to reduce the inspection time cost of single parts. Inspection planning includes two subproblems of viewpoint planning and path planning. To seek the optimal solution of inspection time cost in inspection planning, we propose a multi-objective holistic planning method for viewpoints and paths, which models the viewpoint planning problem and path planning problem as a combinatorial optimization problem for multi-objective optimization. The proposed method performs adaptive redundant sampling of viewpoints based on surface curvature to cope with difficult coverage of complex curved surfaces and constructs a set of sampled viewpoints with both quality and diversity for subsequent inspection planning considered. A constraint-based non-dominated sorting genetic algorithm Ⅱ (C-NSGA-Ⅱ) is put forward for simultaneous optimization of the two objectives of viewpoint coverage and inspection time cost. During the optimization, the viewpoint coverage is constrained to be around the minimum coverage, and the globally optimal solution for the inspection time cost is quickly sought to achieve the holistic planning of viewpoints and paths and minimize the inspection time cost.Results and DiscussionsWe propose a multi-objective holistic planning method for viewpoints and paths. Firstly, a redundant viewpoint sampling method based on surface curvature is proposed in the viewpoint sampling stage. Meanwhile, it is experimentally verified that compared with the commonly adopted random viewpoint sampling method, the viewpoint set sampled by the proposed method has better performance in subsequent inspection planning, which proves that the proposed viewpoint sampling method can construct a higher-quality and diversified sampled viewpoint set (Table 2). Then, C-NSGA-Ⅱ is put forward to carry out holistic planning for the problem of two successive coupling of viewpoint planning and path planning. Compared with the holistic planning method that is simplified into a single-objective optimization problem, the computational efficiency of C-NSGA-Ⅱ is improved by about 90% (Fig. 13). Compared with the traditional individual planning method of viewpoint first and then path, the inspection time cost planned by the proposed method is reduced by more than 10.52% (Table 3). Finally, the effectiveness and superiority of the proposed inspection planning method are verified in robot automated vision inspection applications (Table 4).ConclusionsTo reduce the inspection time cost of automated visual inspection, we propose a multi-objective holistic planning method for viewpoints and paths. The proposed method does not take reducing the number of planned viewpoints as the only goal, but directly takes the viewpoint coverage and inspection time cost as the optimization goals. The above two objectives are globally optimized by C-NSGA-Ⅱ, and the viewpoint set and its path with the optimal inspection time cost are finally planned. Compared with the holistic planning method that is simplified into a single-objective optimization problem, the proposed method does not need to be forced to meet the viewpoint coverage requirements during the optimization, which greatly improves computing efficiency. The experiments prove that the proposed method can quickly solve the global optimal solution compared with individual planning methods and other holistic planning methods, which helps improve the efficiency of automated visual inspection and provides a method for efficient inspection planning in real production. In the subsequent research, on the one hand, the accuracy evaluation index can be added to judge the viewpoints, and on the other hand, the influence of the field environment can be considered to provide feedback on the imaging quality of the viewpoints and make adjustments accordingly. ObjectiveWith the increasing demand for inspecting part surfaces, automated and efficient visual inspection is becoming a trend in industrial production. Due to the complexity of inspection planning problems where both viewpoint planning and path planning belong to the non-determinism of polynomial complexity problem, most of the current research studies the above two problems separately and seeks the minimum viewpoints to satisfy the viewpoint coverage by viewpoint planning, then obtaining efficient inspection paths via path planning for the set of viewpoints. However, viewpoint planning and path planning are coupled problems, and the distribution of viewpoints and paths can easily make the inspection efficiency fall into the local optimum. Therefore, some researchers propose to combine the viewpoint and path planning problems and simplify them into a single objective problem for global optimization, which improves inspection efficiency to a certain extent. However, during the optimization, viewpoints should be continuously added to the viewpoint set to meet the viewpoint coverage, which causes low planning efficiency. To this end, we propose a multi-objective holistic planning method of viewpoints and paths to quickly seek the viewpoint set and its path that satisfy viewpoint coverage and optimal inspection time cost.MethodsIn response to the need for efficient inspection of batch parts, we study the inspection planning method of automated visual inspection to reduce the inspection time cost of single parts. Inspection planning includes two subproblems of viewpoint planning and path planning. To seek the optimal solution of inspection time cost in inspection planning, we propose a multi-objective holistic planning method for viewpoints and paths, which models the viewpoint planning problem and path planning problem as a combinatorial optimization problem for multi-objective optimization. The proposed method performs adaptive redundant sampling of viewpoints based on surface curvature to cope with difficult coverage of complex curved surfaces and constructs a set of sampled viewpoints with both quality and diversity for subsequent inspection planning considered. A constraint-based non-dominated sorting genetic algorithm Ⅱ (C-NSGA-Ⅱ) is put forward for simultaneous optimization of the two objectives of viewpoint coverage and inspection time cost. During the optimization, the viewpoint coverage is constrained to be around the minimum coverage, and the globally optimal solution for the inspection time cost is quickly sought to achieve the holistic planning of viewpoints and paths and minimize the inspection time cost.Results and DiscussionsWe propose a multi-objective holistic planning method for viewpoints and paths. Firstly, a redundant viewpoint sampling method based on surface curvature is proposed in the viewpoint sampling stage. Meanwhile, it is experimentally verified that compared with the commonly adopted random viewpoint sampling method, the viewpoint set sampled by the proposed method has better performance in subsequent inspection planning, which proves that the proposed viewpoint sampling method can construct a higher-quality and diversified sampled viewpoint set (Table 2). Then, C-NSGA-Ⅱ is put forward to carry out holistic planning for the problem of two successive coupling of viewpoint planning and path planning. Compared with the holistic planning method that is simplified into a single-objective optimization problem, the computational efficiency of C-NSGA-Ⅱ is improved by about 90% (Fig. 13). Compared with the traditional individual planning method of viewpoint first and then path, the inspection time cost planned by the proposed method is reduced by more than 10.52% (Table 3). Finally, the effectiveness and superiority of the proposed inspection planning method are verified in robot automated vision inspection applications (Table 4).ConclusionsTo reduce the inspection time cost of automated visual inspection, we propose a multi-objective holistic planning method for viewpoints and paths. The proposed method does not take reducing the number of planned viewpoints as the only goal, but directly takes the viewpoint coverage and inspection time cost as the optimization goals. The above two objectives are globally optimized by C-NSGA-Ⅱ, and the viewpoint set and its path with the optimal inspection time cost are finally planned. Compared with the holistic planning method that is simplified into a single-objective optimization problem, the proposed method does not need to be forced to meet the viewpoint coverage requirements during the optimization, which greatly improves computing efficiency. The experiments prove that the proposed method can quickly solve the global optimal solution compared with individual planning methods and other holistic planning methods, which helps improve the efficiency of automated visual inspection and provides a method for efficient inspection planning in real production. In the subsequent research, on the one hand, the accuracy evaluation index can be added to judge the viewpoints, and on the other hand, the influence of the field environment can be considered to provide feedback on the imaging quality of the viewpoints and make adjustments accordingly.
Acta Optica Sinica
- Publication Date: Feb. 25, 2024
- Vol. 44, Issue 4, 0415001 (2024)
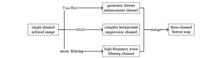
Light Dim Small Target Detection Network with Multi-Heterogeneous Filters
Fei Zhao, and Yingjie Deng
ObjectiveDim small target detection in infrared images with complex backgrounds is a key technology for precise guidance systems and infrared surveillance systems, and the detection performance directly determines the success or failure of tasks. As a result, it has become a hot topic, and different detection methods have been presented. Compared with traditional algorithms, deep network algorithms have achieved remarkable results in many aspects in recent years, and some frameworks designed based on existing deep networks have been applied to detect the dim small target. Although these methods can improve the detection performance of small targets by modifying the network structure because the infrared images have only information of one dimension and limited features in small targets, it is difficult to obtain satisfactory results when the deep network is directly applied to detect dim small targets in the complex infrared background, and the large network scale makes it difficult to deploy the above methods on the embedded platform with constrained resources.MethodsIn view of the characteristics of single information dimension in infrared images and inconspicuous features of dim small targets, this study enriches the information of original images and incorporates multiple filters with different structures into the YOLOv5n network. In this study, three filters with different structures, namely the Top Hat filter, difference of Gaussian filter (DoG), and mean filter, are selected from the perspective of highlighting targets, suppressing backgrounds, and filtering high-frequency noises. By introducing three heterogeneous filters to process the images in the input layer of the network, the one-dimensional gray information of the original image is expanded into three dimensions, and then they are fed to the network through three channels, which improves the adaptability of the network to dim small targets in complex backgrounds.YOLOV5n network is selected in this study and improved as follows. 1) In order to make the deep network improve the feature weight of the region of interest and suppress the response of the unrelated region during training, the lightweight convolutional block attention module (CBAM) is added to the backbone of YOLOv5n so that the extracted feature map can play a greater role in the subsequent target extraction. The output in the convolution layer first passes through the channel attention module (CAM) to improve the weight of target-related features and then through the spatial attention module (SAM), which enables the weighted feature to remain in the deeper network. 2) In the standard YOLOV5n network, target detection is carried out using the feature maps of P17, P20, and P23 layers. In the process of target extraction, targets are searched and selected through preset anchor boxes of different sizes. Since the shallow network has a feature map with a large size and contains rich original information, it is conducive to small target detection. Therefore, this study adjusts the size of the anchor in P3 layer to [5, 6, 6, 8, 9, 11], which is beneficial to small target detection. 3) The perception field of view of the shallow network is small, which is conducive to extracting the local features of the target. The deep network has a large perception field of view, which is mainly used to extract the global features of the target. For the application scenario of small target detection, the features extracted by the deep network are limited and may even interfere with the final detection results. After multi-layer feature extraction of the backbone network, the deep network almost does not contain small target features, so the standard YOLOv5n network is cropped to remove P5-P23 layers, and only P3-P17 and P4-P20 output features are used for detection. By adding attention modules, adopting small anchor strategies, and cutting deep branches of the network, the dim small target detection performance of the YOLOv5n network is improved, and the consumption of computational and storage resources is reduced.Results and DiscussionsIn order to verify the performance of the algorithm, this study selects the dim small target detection and tracking infrared dataset against the ground/air background. Multiple deep network algorithms dedicated to small target detection are selected for comparison. Furthermore, the classical target detection network algorithms which are modified for small target detection are selected. In terms of detection performance, the proposed algorithm obtains the second-highest average precision (AP) value of 0.888, which is 1.4% lower than the highest value and 3% higher than the third-highest value. In terms of network size and computational efficiency, the proposed algorithm achieves the fastest processing speed of 416 frame/s at the smallest network size (3 MB), and the network size is half that of the algorithm in Ref. [7]. Compared with the algorithm with the best detection performance, the proposed algorithm performs approximately 60 times more efficiently, and the network size is approximately 1/16. This study analyzes the performance gains of improvement measures, such as introducing multi-heterogeneous filters, adding attention modules and small anchor box strategies, and cropping deep networks. The experimental results show that the proposed algorithm can still maintain an excellent detection performance with the smallest parameter size and the highest operational efficiency.ConclusionsIn order to improve the detection performance of dim small targets and enhance the deployment ability of algorithms, a light dim small target detection network with multi-heterogeneous filters is proposed. Experimental results show that the proposed algorithm can detect dim small targets in the complex infrared background effectively. In addition, fewer computational and storage resources are consumed, which lays a foundation for deployment on the embedded platform with constrained resources. ObjectiveDim small target detection in infrared images with complex backgrounds is a key technology for precise guidance systems and infrared surveillance systems, and the detection performance directly determines the success or failure of tasks. As a result, it has become a hot topic, and different detection methods have been presented. Compared with traditional algorithms, deep network algorithms have achieved remarkable results in many aspects in recent years, and some frameworks designed based on existing deep networks have been applied to detect the dim small target. Although these methods can improve the detection performance of small targets by modifying the network structure because the infrared images have only information of one dimension and limited features in small targets, it is difficult to obtain satisfactory results when the deep network is directly applied to detect dim small targets in the complex infrared background, and the large network scale makes it difficult to deploy the above methods on the embedded platform with constrained resources.MethodsIn view of the characteristics of single information dimension in infrared images and inconspicuous features of dim small targets, this study enriches the information of original images and incorporates multiple filters with different structures into the YOLOv5n network. In this study, three filters with different structures, namely the Top Hat filter, difference of Gaussian filter (DoG), and mean filter, are selected from the perspective of highlighting targets, suppressing backgrounds, and filtering high-frequency noises. By introducing three heterogeneous filters to process the images in the input layer of the network, the one-dimensional gray information of the original image is expanded into three dimensions, and then they are fed to the network through three channels, which improves the adaptability of the network to dim small targets in complex backgrounds.YOLOV5n network is selected in this study and improved as follows. 1) In order to make the deep network improve the feature weight of the region of interest and suppress the response of the unrelated region during training, the lightweight convolutional block attention module (CBAM) is added to the backbone of YOLOv5n so that the extracted feature map can play a greater role in the subsequent target extraction. The output in the convolution layer first passes through the channel attention module (CAM) to improve the weight of target-related features and then through the spatial attention module (SAM), which enables the weighted feature to remain in the deeper network. 2) In the standard YOLOV5n network, target detection is carried out using the feature maps of P17, P20, and P23 layers. In the process of target extraction, targets are searched and selected through preset anchor boxes of different sizes. Since the shallow network has a feature map with a large size and contains rich original information, it is conducive to small target detection. Therefore, this study adjusts the size of the anchor in P3 layer to [5, 6, 6, 8, 9, 11], which is beneficial to small target detection. 3) The perception field of view of the shallow network is small, which is conducive to extracting the local features of the target. The deep network has a large perception field of view, which is mainly used to extract the global features of the target. For the application scenario of small target detection, the features extracted by the deep network are limited and may even interfere with the final detection results. After multi-layer feature extraction of the backbone network, the deep network almost does not contain small target features, so the standard YOLOv5n network is cropped to remove P5-P23 layers, and only P3-P17 and P4-P20 output features are used for detection. By adding attention modules, adopting small anchor strategies, and cutting deep branches of the network, the dim small target detection performance of the YOLOv5n network is improved, and the consumption of computational and storage resources is reduced.Results and DiscussionsIn order to verify the performance of the algorithm, this study selects the dim small target detection and tracking infrared dataset against the ground/air background. Multiple deep network algorithms dedicated to small target detection are selected for comparison. Furthermore, the classical target detection network algorithms which are modified for small target detection are selected. In terms of detection performance, the proposed algorithm obtains the second-highest average precision (AP) value of 0.888, which is 1.4% lower than the highest value and 3% higher than the third-highest value. In terms of network size and computational efficiency, the proposed algorithm achieves the fastest processing speed of 416 frame/s at the smallest network size (3 MB), and the network size is half that of the algorithm in Ref. [7]. Compared with the algorithm with the best detection performance, the proposed algorithm performs approximately 60 times more efficiently, and the network size is approximately 1/16. This study analyzes the performance gains of improvement measures, such as introducing multi-heterogeneous filters, adding attention modules and small anchor box strategies, and cropping deep networks. The experimental results show that the proposed algorithm can still maintain an excellent detection performance with the smallest parameter size and the highest operational efficiency.ConclusionsIn order to improve the detection performance of dim small targets and enhance the deployment ability of algorithms, a light dim small target detection network with multi-heterogeneous filters is proposed. Experimental results show that the proposed algorithm can detect dim small targets in the complex infrared background effectively. In addition, fewer computational and storage resources are consumed, which lays a foundation for deployment on the embedded platform with constrained resources.
Acta Optica Sinica
- Publication Date: May. 10, 2023
- Vol. 43, Issue 9, 0915001 (2023)

Simplified Multi-Channel Parallel Optical Performance Monitoring Based on Deep Learning
Mengyan Li, Jintao Wu, Jingyu Yang, Lifu Zhang, Yong Tan, Tian Qiu, Yuebin Li, Heming Deng, Fengguang Luo, and Liu Yang
ObjectiveAs emerging services have a higher demand for internet performance, high-capacity, multi-channel, and flexible fiber optic communication systems have become the trend of optical communications with the advantages of dynamic, high-capacity, and transparent transmission. Complex link impairments in large-capacity and multi-channel optical communication systems put forward higher requirements for optical performance monitoring (OPM) technology. The number of monitoring parameters and links of OPM needs to be increased continuously with a higher monitoring accuracy and a larger dynamic range. In the previous papers, existing monitoring mechanisms for optical fiber communications focus on OPM performance and are still dominated by single-channel monitoring schemes. The so-called multi-channel monitoring schemes are operated sequentially by selecting specific channels through tunable optical filters, which may introduce measurement delays for multi-channel systems such as wavelength division multiplexing (WDM) systems. Besides, in next-generation dynamically reconfigurable optical networks, OPM is also conducted on intermediate nodes except for the receiver. Obviously, there are few studies on this flexible OPM. In order to meet these demands for future OPM schemes, it is necessary to develop OPM that can be used for multi-channel monitoring with portability, low complexity, and high accuracy. Therefore, a simplified multi-channel parallel OPM scheme is proposed based on deep learning to overcome the shortcomings in multi-channel monitoring.MethodsIn this paper, a multi-channel parallel OPM scheme based on signal spectrum and multi-task deep neural network (MT-DNN) is proposed to deal with the shortcomings of the multi-channel OPM. This scheme processes the collected multi-channel spectrum from the fiber link by downsampling, filtering, signal waveform separation, and power normalization. Then, the number of signal sample points is counted based on each power value interval to generate amplitude histograms (Ahs). The Keras library in the TensorFlow deep learning framework (version 2.0) is used to build an MT-DNN model. Since Ahs reflect the statistical distribution of signal amplitude, the bin number vector of Ahs is used as the input of MT-DNN for training, which can realize the multi-channel modulation format identification (MFI) and optical signal-to-noise ratio (OSNR) monitoring of a WDM system. In order to further investigate the performance of this OPM scheme and cope with the complex transmission environment, a transfer learning-assisted multi-task deep neural network (TL-MT-DNN) is proposed for parallel monitoring of multi-channel MFI and OSNR. This paper shares the parameters of the MT-DNN model in the source domain (DS) except for the output layer to the TL-MT-DNN model in the target domain (DT) to replace random initialization of the network parameters. The parameters of the output layer of the TL-MT-DNN model are randomly initialized. The parameters of the TL-MT-DNN model are tuned for better monitoring performance by using Fine-Tuning, a parameter-tuning method commonly used in transfer learning.Results and DiscussionsThe proposed MT-DNN model for multi-channel parallel MFI and OSNR monitoring is demonstrated in this paper. In the established three-channel WDM coherent optical communication system, an accurate monitoring with MFI accuracy of 100% and mean absolute error (MAE) of 0.16 dB for OSNR monitoring is achieved for three-channel signals with ten modulation formats combined by PDM-4QAM/16QAM/64QAM (Fig. 10 and Fig. 11). In order to deal with a more complex transmission environment, the paper transfers the parameters of MT-DNN to TL-MT-DNN to achieve parallel monitoring of multi-channel MFI and OSNR according to the principle described in Fig. 5. This scheme has better portability and saves a large number of samples and training epochs (Fig. 12). The MFI accuracy can reach 100%, and the MAE of three-channel OSNR monitoring is 0.24 dB, 0.20 dB, and 0.19 dB, respectively (Fig. 13). The results show that the simplified multi-channel parallel OPM scheme based on deep learning proposed in this paper can monitor the multi-channel optical system without processing each channel individually and requiring additional filtering equipment. The scheme can be extended to any node of the fiber optic link or receiver side to achieve multi-channel monitoring, which is suitable for future high-capacity and elastic optical transmission systems.ConclusionsThis paper proposes a multi-channel OPM technique based on signal spectrum and MT-DNN at the intermediate node of the WDM system for multi-parameter parallel monitoring of high-capacity multi-channel optical networks. The method can monitor multi-channel OPM without processing each channel individually. The performance of this scheme is demonstrated, and the scheme can accurately monitor multi-channel signals. The influence of hyperparameters of MT-DNN (weighting factor of each task, optimizer, and training set size) on its monitoring performance is studied. In order to verify the portability of this OPM scheme for complex transmission environments, a TL-MT-DNN model is proposed and demonstrated with a low training cost and low implementation complexity. The results show that the proposed intelligent OPM scheme requiring only one spectrometer and a single MT-DNN can achieve accurate multi-channel monitoring, which can be extended to any node of the fiber optic link or receiver side to achieve accurate monitoring. Due to these advantages, this method provides a certain research reference for future flexible and high-capacity optical network performance monitoring. ObjectiveAs emerging services have a higher demand for internet performance, high-capacity, multi-channel, and flexible fiber optic communication systems have become the trend of optical communications with the advantages of dynamic, high-capacity, and transparent transmission. Complex link impairments in large-capacity and multi-channel optical communication systems put forward higher requirements for optical performance monitoring (OPM) technology. The number of monitoring parameters and links of OPM needs to be increased continuously with a higher monitoring accuracy and a larger dynamic range. In the previous papers, existing monitoring mechanisms for optical fiber communications focus on OPM performance and are still dominated by single-channel monitoring schemes. The so-called multi-channel monitoring schemes are operated sequentially by selecting specific channels through tunable optical filters, which may introduce measurement delays for multi-channel systems such as wavelength division multiplexing (WDM) systems. Besides, in next-generation dynamically reconfigurable optical networks, OPM is also conducted on intermediate nodes except for the receiver. Obviously, there are few studies on this flexible OPM. In order to meet these demands for future OPM schemes, it is necessary to develop OPM that can be used for multi-channel monitoring with portability, low complexity, and high accuracy. Therefore, a simplified multi-channel parallel OPM scheme is proposed based on deep learning to overcome the shortcomings in multi-channel monitoring.MethodsIn this paper, a multi-channel parallel OPM scheme based on signal spectrum and multi-task deep neural network (MT-DNN) is proposed to deal with the shortcomings of the multi-channel OPM. This scheme processes the collected multi-channel spectrum from the fiber link by downsampling, filtering, signal waveform separation, and power normalization. Then, the number of signal sample points is counted based on each power value interval to generate amplitude histograms (Ahs). The Keras library in the TensorFlow deep learning framework (version 2.0) is used to build an MT-DNN model. Since Ahs reflect the statistical distribution of signal amplitude, the bin number vector of Ahs is used as the input of MT-DNN for training, which can realize the multi-channel modulation format identification (MFI) and optical signal-to-noise ratio (OSNR) monitoring of a WDM system. In order to further investigate the performance of this OPM scheme and cope with the complex transmission environment, a transfer learning-assisted multi-task deep neural network (TL-MT-DNN) is proposed for parallel monitoring of multi-channel MFI and OSNR. This paper shares the parameters of the MT-DNN model in the source domain (DS) except for the output layer to the TL-MT-DNN model in the target domain (DT) to replace random initialization of the network parameters. The parameters of the output layer of the TL-MT-DNN model are randomly initialized. The parameters of the TL-MT-DNN model are tuned for better monitoring performance by using Fine-Tuning, a parameter-tuning method commonly used in transfer learning.Results and DiscussionsThe proposed MT-DNN model for multi-channel parallel MFI and OSNR monitoring is demonstrated in this paper. In the established three-channel WDM coherent optical communication system, an accurate monitoring with MFI accuracy of 100% and mean absolute error (MAE) of 0.16 dB for OSNR monitoring is achieved for three-channel signals with ten modulation formats combined by PDM-4QAM/16QAM/64QAM (Fig. 10 and Fig. 11). In order to deal with a more complex transmission environment, the paper transfers the parameters of MT-DNN to TL-MT-DNN to achieve parallel monitoring of multi-channel MFI and OSNR according to the principle described in Fig. 5. This scheme has better portability and saves a large number of samples and training epochs (Fig. 12). The MFI accuracy can reach 100%, and the MAE of three-channel OSNR monitoring is 0.24 dB, 0.20 dB, and 0.19 dB, respectively (Fig. 13). The results show that the simplified multi-channel parallel OPM scheme based on deep learning proposed in this paper can monitor the multi-channel optical system without processing each channel individually and requiring additional filtering equipment. The scheme can be extended to any node of the fiber optic link or receiver side to achieve multi-channel monitoring, which is suitable for future high-capacity and elastic optical transmission systems.ConclusionsThis paper proposes a multi-channel OPM technique based on signal spectrum and MT-DNN at the intermediate node of the WDM system for multi-parameter parallel monitoring of high-capacity multi-channel optical networks. The method can monitor multi-channel OPM without processing each channel individually. The performance of this scheme is demonstrated, and the scheme can accurately monitor multi-channel signals. The influence of hyperparameters of MT-DNN (weighting factor of each task, optimizer, and training set size) on its monitoring performance is studied. In order to verify the portability of this OPM scheme for complex transmission environments, a TL-MT-DNN model is proposed and demonstrated with a low training cost and low implementation complexity. The results show that the proposed intelligent OPM scheme requiring only one spectrometer and a single MT-DNN can achieve accurate multi-channel monitoring, which can be extended to any node of the fiber optic link or receiver side to achieve accurate monitoring. Due to these advantages, this method provides a certain research reference for future flexible and high-capacity optical network performance monitoring.
Acta Optica Sinica
- Publication Date: Apr. 10, 2023
- Vol. 43, Issue 7, 0715002 (2023)
Light Field Deconvolution Algorithm for Three-Dimensional Plasma Reconstruction
Heng Zhang, Lü Xue, Hua Li, and Qin Hang
ObjectiveIdentifying and reconstructing fusion plasma boundaries accurately are important research areas in controlled thermonuclear fusion. The traditional electromagnetic measurement methods will inevitably suffer from the accuracy problem arising from neutron radiation and long-term drift. The traditional optical diagnostic methods are non-intrusive and reach a high level of spatial resolution. However, they are commonly limited to two-dimensional imaging. As the processes within the plasma flow are inherently three-dimensional, it is necessary to develop a three-dimensional method for plasma measurement. In order to capture the dynamic information of the plasma and avoid signal distortion, three-dimensional imaging must be achieved at a high speed in parallel or sequential imaging of multiple planes. However, the existing three-dimensional reconstruction methods based on tomography technology are limited by spatial and temporal resolution, and multiple images have to be captured from various angles, or complex experimental setups are needed. All the above methods are not applicable to reconstructing the three-dimensional plasma boundaries in real time. The light field camera is an emerging image acquisition device, in which a microlens array is placed between the main lens and the sensor. With the light field camera, multi-angle information can be captured within a single exposure. Plasma flow is the typical semi-transparent and dispersive media. To date, some studies have used the light field deconvolution algorithm to reconstruct the plasma, but the algorithm requires a long computation time. To this end, we propose a light field deconvolution algorithm based on optical sectioning imaging, which has the advantages of simplicity and speed. We hope that our method can be helpful in the three-dimensional reconstruction of plasma.MethodsThe depth information and point spread function are the key parameters of the method in this paper. We obtain these two parameters through experiments. First of all, with the digital refocusing technology, we calculate the relationship between the light-field refocused parameters and real-world depth by using the scale and the image sharpness evaluation algorithm. Then, we determine five points to calculate refocused section images, and by the edge method, the point spread function at these locations is computed for the subsequent iterative deconvolution operation. Finally, we perform the deconvolution operation on the image to be reconstructed and the point spread function to remove the out-of-focus information from the image to be reconstructed.Results and DiscussionsIn order to verify the effectiveness of the proposed method, simulation experiments are conducted. The defocusing effect is simulated by setting different point diffusion functions and image convolution (Fig. 14). The simulation results show that the proposed method can effectively remove the out-of-focus image information. In addition, the effect of the number of sections and section intervals on the reconstruction accuracy is explored, and the structural similarity (SSIM) is used to evaluate the performance (Figs. 16 and 17). The results show that as more sections are involved in the deconvolution, and the spacing gets smaller, the reconstruction performance becomes better. Finally, an experiment with the flame is conducted as the research object. The proposed method recovers the original structure of the section image successfully, and the trend is consistent with the actual flame distribution (Fig. 22), which verifies the experimental efficacy of the proposed reconstruction method.ConclusionsIn order to address the problems in traditional optical diagnostic techniques such as three-dimensional information loss and poor real-time performance, a light field deconvolution method based on optical sectioning imaging is proposed, so as to achieve the three-dimensional reconstruction of plasma boundaries by a single camera without focus adjustment. The three-dimensional reconstruction is transformed into the two-dimensional section reconstruction, which reduces the computational cost greatly. The results show that the original section image of the flame can be reconstructed by the proposed method, which initially demonstrates the feasibility of the three-dimensional reconstruction method of the plasma based on light field imaging. With the optical imaging conditions in this paper as an example, the depth-of-field resolution of the three-dimensional reconstructed object should be close to the depth of the object within the focal plane, and for high depth-of-field resolution, 100 or more focal planes are likely to be required to span the full depth of the object, while only five sections are selected to verify the effectiveness of the proposed method. To further improve the spatio-temporal resolution of the reconstruction, we will make attempts to achieve a more accurate extraction of the point spread function by using a high-precision electrodynamic displacement stage and performing deconvolution operations with more section images. ObjectiveIdentifying and reconstructing fusion plasma boundaries accurately are important research areas in controlled thermonuclear fusion. The traditional electromagnetic measurement methods will inevitably suffer from the accuracy problem arising from neutron radiation and long-term drift. The traditional optical diagnostic methods are non-intrusive and reach a high level of spatial resolution. However, they are commonly limited to two-dimensional imaging. As the processes within the plasma flow are inherently three-dimensional, it is necessary to develop a three-dimensional method for plasma measurement. In order to capture the dynamic information of the plasma and avoid signal distortion, three-dimensional imaging must be achieved at a high speed in parallel or sequential imaging of multiple planes. However, the existing three-dimensional reconstruction methods based on tomography technology are limited by spatial and temporal resolution, and multiple images have to be captured from various angles, or complex experimental setups are needed. All the above methods are not applicable to reconstructing the three-dimensional plasma boundaries in real time. The light field camera is an emerging image acquisition device, in which a microlens array is placed between the main lens and the sensor. With the light field camera, multi-angle information can be captured within a single exposure. Plasma flow is the typical semi-transparent and dispersive media. To date, some studies have used the light field deconvolution algorithm to reconstruct the plasma, but the algorithm requires a long computation time. To this end, we propose a light field deconvolution algorithm based on optical sectioning imaging, which has the advantages of simplicity and speed. We hope that our method can be helpful in the three-dimensional reconstruction of plasma.MethodsThe depth information and point spread function are the key parameters of the method in this paper. We obtain these two parameters through experiments. First of all, with the digital refocusing technology, we calculate the relationship between the light-field refocused parameters and real-world depth by using the scale and the image sharpness evaluation algorithm. Then, we determine five points to calculate refocused section images, and by the edge method, the point spread function at these locations is computed for the subsequent iterative deconvolution operation. Finally, we perform the deconvolution operation on the image to be reconstructed and the point spread function to remove the out-of-focus information from the image to be reconstructed.Results and DiscussionsIn order to verify the effectiveness of the proposed method, simulation experiments are conducted. The defocusing effect is simulated by setting different point diffusion functions and image convolution (Fig. 14). The simulation results show that the proposed method can effectively remove the out-of-focus image information. In addition, the effect of the number of sections and section intervals on the reconstruction accuracy is explored, and the structural similarity (SSIM) is used to evaluate the performance (Figs. 16 and 17). The results show that as more sections are involved in the deconvolution, and the spacing gets smaller, the reconstruction performance becomes better. Finally, an experiment with the flame is conducted as the research object. The proposed method recovers the original structure of the section image successfully, and the trend is consistent with the actual flame distribution (Fig. 22), which verifies the experimental efficacy of the proposed reconstruction method.ConclusionsIn order to address the problems in traditional optical diagnostic techniques such as three-dimensional information loss and poor real-time performance, a light field deconvolution method based on optical sectioning imaging is proposed, so as to achieve the three-dimensional reconstruction of plasma boundaries by a single camera without focus adjustment. The three-dimensional reconstruction is transformed into the two-dimensional section reconstruction, which reduces the computational cost greatly. The results show that the original section image of the flame can be reconstructed by the proposed method, which initially demonstrates the feasibility of the three-dimensional reconstruction method of the plasma based on light field imaging. With the optical imaging conditions in this paper as an example, the depth-of-field resolution of the three-dimensional reconstructed object should be close to the depth of the object within the focal plane, and for high depth-of-field resolution, 100 or more focal planes are likely to be required to span the full depth of the object, while only five sections are selected to verify the effectiveness of the proposed method. To further improve the spatio-temporal resolution of the reconstruction, we will make attempts to achieve a more accurate extraction of the point spread function by using a high-precision electrodynamic displacement stage and performing deconvolution operations with more section images.
Acta Optica Sinica
- Publication Date: Apr. 10, 2023
- Vol. 43, Issue 7, 0715001 (2023)
Deep Transfer Learning-Based Pulsed Eddy Current Thermography for Crack Defect Detection
Baiqiao Hao, Yugang Fan, and Zhihuan Song
Results and Discussions The experiments are conducted on the Google Colab with a deep learning framework of Pytorch 1.7 and a Tesla T4 GPU with 16 GB RAM. In this paper, precision, recall, mean average precision (mAP), and frames rate are taken as model evaluation indicators. In the first comparison experiment, the loss function of the model with the proposed transfer learning method decreases more rapidly and the model converges more stably (Fig. 6). The testing results show that the recall and mAP of the model obtained by the proposed method are improved by 16.5% and 8.9%, respectively (Table 3), proving the effectiveness of the proposed method. In the second comparison experiment, the ASFF-YOLO v5 model has a higher mAP than the baseline, while the loss function decreases faster and the value of the loss function after stability is smaller (Fig. 7). The testing results show that although adaptive spatial feature fusion module increases floating point operations (FLOPs) and leads to a decrease in FPS, the recall of ASFF-YOLO v5 is increased by 11.7%, which effectively overcomes the defect miss detection; the mAP value is increased by 6.2% (Table 4), and the model performance is significantly improved in the recognition and localization of crack defects.1) Through the projection method of target domain feature space, images with similar defect features are selected from the source domain for pre-training the YOLO v5 defect detection model. Then target domain images are adopted to fine-tune the pre-trained model to realize knowledge transfer between similar domains, which solves the problem of insufficient defect samples during model training. The mAP of the transfer learning model is improved by 8.9%, which proves the feasibility of the proposed method.2) The capability of the YOLO v5 model to fuse multi-scale features has been enhanced by the introduction of ASFF. In the comparison experiments, the recall of ASFF-YOLO v5 is improved by 11.7%, which effectively overcomes the miss detection and verifies the accuracy of the method.However, when the crack defect is not obvious or generated in the complex infrared background, the false detection of individual defect sample types may occur. In the future, we will try to introduce attention mechanism to suppress background noise and improve the accuracy of defect detection.ObjectiveMany key components of mechanical equipment are made of metallic materials. During long-term service, cracks, scratches, pits, and other damages may occur on the surfaces or inside metallic materials. Under the action of the external environment and stress, the damages easily extend to the surrounding area, resulting in more harmful defects with more complicated structures. Therefore, the research on nondestructive testing for steel materials is of great significance to improve the reliability of equipment and prevent catastrophic accidents. Pulsed eddy current thermography has been successfully applied as a visual nondestructive testing method for defect detection in steel materials. The principle is that defects in steel materials affect the distribution of induced eddy currents, which in turn causes changes in the temperature field distribution. However, to ensure the safe operation of the equipment, the actual production often follows a regular cycle of equipment maintenance and component replacement. As a result, a few defect images are collected by pulsed eddy current thermography, and then the defect detection model constructed by the small number of samples suffers from inadequate training, insufficient model generalization, and low defect detection accuracy.MethodsIn this study, the construction of the defect detection model based on deep transfer learning is proposed. First, a typical defect sample database is formed by selecting part of infrared images in the target domain, and the target domain feature space is constructed by extracting the defect features through non-negative matrix factorization. Then, the source domain defect images are projected into the target domain feature space, and the images with similar defect features are selected by cosine similarity. In addition, the obtained source domain images are used for pre-training the YOLO v5 defect detection model, and the model weight parameters are transferred to the target domain to realize knowledge transfer in similar domains. Finally, the adaptively spatial feature fusion (ASFF) module is introduced to the YOLO v5 algorithm, and the ASFF-YOLO v5 model is fine-tuned with the training set samples in the target domain and validated with the test set samples to obtain the final crack defect detection model in the target domain.ConclusionsIn this study, a deep transfer learning method for crack defect detection is proposed. Under the experimental platform of this paper, for defect images with a resolution of 320 pixel×240 pixel, the mAP of this model reaches 98.6% and the detection speed is 46 frame/s, which provides references for the development of pulsed eddy current thermography technology toward high efficiency and visualization. The major contributions of this study are summarized as follows. Results and Discussions The experiments are conducted on the Google Colab with a deep learning framework of Pytorch 1.7 and a Tesla T4 GPU with 16 GB RAM. In this paper, precision, recall, mean average precision (mAP), and frames rate are taken as model evaluation indicators. In the first comparison experiment, the loss function of the model with the proposed transfer learning method decreases more rapidly and the model converges more stably (Fig. 6). The testing results show that the recall and mAP of the model obtained by the proposed method are improved by 16.5% and 8.9%, respectively (Table 3), proving the effectiveness of the proposed method. In the second comparison experiment, the ASFF-YOLO v5 model has a higher mAP than the baseline, while the loss function decreases faster and the value of the loss function after stability is smaller (Fig. 7). The testing results show that although adaptive spatial feature fusion module increases floating point operations (FLOPs) and leads to a decrease in FPS, the recall of ASFF-YOLO v5 is increased by 11.7%, which effectively overcomes the defect miss detection; the mAP value is increased by 6.2% (Table 4), and the model performance is significantly improved in the recognition and localization of crack defects.1) Through the projection method of target domain feature space, images with similar defect features are selected from the source domain for pre-training the YOLO v5 defect detection model. Then target domain images are adopted to fine-tune the pre-trained model to realize knowledge transfer between similar domains, which solves the problem of insufficient defect samples during model training. The mAP of the transfer learning model is improved by 8.9%, which proves the feasibility of the proposed method.2) The capability of the YOLO v5 model to fuse multi-scale features has been enhanced by the introduction of ASFF. In the comparison experiments, the recall of ASFF-YOLO v5 is improved by 11.7%, which effectively overcomes the miss detection and verifies the accuracy of the method.However, when the crack defect is not obvious or generated in the complex infrared background, the false detection of individual defect sample types may occur. In the future, we will try to introduce attention mechanism to suppress background noise and improve the accuracy of defect detection.ObjectiveMany key components of mechanical equipment are made of metallic materials. During long-term service, cracks, scratches, pits, and other damages may occur on the surfaces or inside metallic materials. Under the action of the external environment and stress, the damages easily extend to the surrounding area, resulting in more harmful defects with more complicated structures. Therefore, the research on nondestructive testing for steel materials is of great significance to improve the reliability of equipment and prevent catastrophic accidents. Pulsed eddy current thermography has been successfully applied as a visual nondestructive testing method for defect detection in steel materials. The principle is that defects in steel materials affect the distribution of induced eddy currents, which in turn causes changes in the temperature field distribution. However, to ensure the safe operation of the equipment, the actual production often follows a regular cycle of equipment maintenance and component replacement. As a result, a few defect images are collected by pulsed eddy current thermography, and then the defect detection model constructed by the small number of samples suffers from inadequate training, insufficient model generalization, and low defect detection accuracy.MethodsIn this study, the construction of the defect detection model based on deep transfer learning is proposed. First, a typical defect sample database is formed by selecting part of infrared images in the target domain, and the target domain feature space is constructed by extracting the defect features through non-negative matrix factorization. Then, the source domain defect images are projected into the target domain feature space, and the images with similar defect features are selected by cosine similarity. In addition, the obtained source domain images are used for pre-training the YOLO v5 defect detection model, and the model weight parameters are transferred to the target domain to realize knowledge transfer in similar domains. Finally, the adaptively spatial feature fusion (ASFF) module is introduced to the YOLO v5 algorithm, and the ASFF-YOLO v5 model is fine-tuned with the training set samples in the target domain and validated with the test set samples to obtain the final crack defect detection model in the target domain.ConclusionsIn this study, a deep transfer learning method for crack defect detection is proposed. Under the experimental platform of this paper, for defect images with a resolution of 320 pixel×240 pixel, the mAP of this model reaches 98.6% and the detection speed is 46 frame/s, which provides references for the development of pulsed eddy current thermography technology toward high efficiency and visualization. The major contributions of this study are summarized as follows.
Acta Optica Sinica
- Publication Date: Feb. 25, 2023
- Vol. 43, Issue 4, 0415002 (2023)
Photonic Convolutional Neural Network Accelerator Assisted by Phase Change Material
Pengxing Guo, Zhiyuan Liu, Weigang Hou, and Lei Guo
Results and Discussions As a proof of concept, a 4×4 optical matrix multiplication with 10 Gb/s and 20 Gb/s data rates is verified by the simulation platform Ansys Lumerical. Four wavelengths are used as the input pulse, which is a binary sequence composed of 0 or 1. The output value obtained by optical simulation has a high fit with the theoretical calculation value (Fig. 6). Then, the NVSP-CNN is compared with the DEAP-CNN structure in terms of the rate, area, power consumption, and accuracy. Similar to the case of DEAP-CNN, the computing rate of the NVSP structure is limited by the digital-to-analog converter (DAC) modulation rate. The highest operation rate can reach 5 GSa/s, which is faster than the operation rate of the mainstream GPU. Compared with DEAP-CNN, the proposed accelerator structure can reduce power consumption by 48.75% while maintaining the original operation speed, and the area at the matrix operation can be reduced by 49.75%. Finally, the simulations on the MNIST and notMNIST datasets are performed, and inference accuracies of 97.80% and 92.45% are achieved, respectively. The recognition results show that the accelerator structure can complete most image recognition tasks in life.ObjectiveThe convolutional neural network (CNN) has achieved great success in computer vision and image and speech processing due to its high recognition accuracy. This success cannot be separated from the support of the hardware accelerator. However, the rapid development of artificial intelligence has led to a dramatic increase in the amount of data, which places stricter requirements on the computing power of hardware accelerators. Limited by the power and speed of electronic devices, traditional electronic accelerators can hardly meet the requirements of hardware computing power and energy consumption for large-scale computing operations. As an alternative, micro-ring resonator (MRR) and Mach-Zehnder interferometer (MZI)-based silicon photonic accelerators provide an effective solution to the problem faced by electronic accelerators. However, prior photonic accelerators need to read the weights from the external memory when performing the multiply-accumulate operation and mapping each value to the bias voltage of the MRR or MZI units, which increases the area and energy consumption. To solve the above problems, this paper proposes a nonvolatile silicon photonic convolutional neural network (NVSP-CNN) accelerator. This structure uses the Add-Drop MRR and nonvolatile phase change material Ge2Sb2Te5 (GST) to realize optical in-memory computing, which helps improve energy efficiency and computing density.MethodsFirstly, we design a photonic dot-product engine on the basis of GST and the Add-Drop MRR (Fig. 2). The GST is embedded on the top of the MRR, and its different crystallization degrees are used to change the refractive index of the MRR, which makes the output power of the Through and Drop ports change. The crystallization degree of GST is modulated outside the chip, and the light pulse increases the internal temperature of GST to change the crystallization degree. It is then cooled rapidly so that the crystallization state is preserved. This value remains unchanged for a long time without external current. During computational operations, a short and low-power optical pulse is injected from the MRR's input port and output from the Drop and Through ports. The output optical power is converted to electric power through a balanced photodiode, and Td-Tp is realized in the meantime. Therefore, the values of Td-Tp under different GST phase states can be used as the weight values in the neural network (Fig. 3). Then, we propose an optical matrix multiplier combined with wavelength division multiplexing (WDM) technology and the GST-MRR-based photonic dot-product engine (Fig. 4). Finally, the optical matrix multiplier is combined with the nonlinear parts (activation, pooling, and full connectivity) to build a complete accelerator, i.e., the NVSP-CNN accelerator (Fig. 5). In NVSP-CNN, the convolution operation is implemented optically, and the nonlinear part is realized electrically.ConclusionsThis paper proposes an MRR and GST-based photonic CNN accelerator structure for in-memory computing. Unlike the traditional MRR-based accelerator, the NVSP-CNN accelerator can avoid the power loss caused by the continuous external power supply for state maintenance and does not require external electrical pads for modulation. Hence, it can effectively reduce area loss. In addition, we implement the simulations on the MNIST and notMNIST datasets and achieve inference accuracies of 97.80% and 92.45%, respectively. Therefore, the proposed structure has advantages in power consumption, area loss, and recognition accuracy, which is expected to tackle most image recognition tasks in the future. Results and Discussions As a proof of concept, a 4×4 optical matrix multiplication with 10 Gb/s and 20 Gb/s data rates is verified by the simulation platform Ansys Lumerical. Four wavelengths are used as the input pulse, which is a binary sequence composed of 0 or 1. The output value obtained by optical simulation has a high fit with the theoretical calculation value (Fig. 6). Then, the NVSP-CNN is compared with the DEAP-CNN structure in terms of the rate, area, power consumption, and accuracy. Similar to the case of DEAP-CNN, the computing rate of the NVSP structure is limited by the digital-to-analog converter (DAC) modulation rate. The highest operation rate can reach 5 GSa/s, which is faster than the operation rate of the mainstream GPU. Compared with DEAP-CNN, the proposed accelerator structure can reduce power consumption by 48.75% while maintaining the original operation speed, and the area at the matrix operation can be reduced by 49.75%. Finally, the simulations on the MNIST and notMNIST datasets are performed, and inference accuracies of 97.80% and 92.45% are achieved, respectively. The recognition results show that the accelerator structure can complete most image recognition tasks in life.ObjectiveThe convolutional neural network (CNN) has achieved great success in computer vision and image and speech processing due to its high recognition accuracy. This success cannot be separated from the support of the hardware accelerator. However, the rapid development of artificial intelligence has led to a dramatic increase in the amount of data, which places stricter requirements on the computing power of hardware accelerators. Limited by the power and speed of electronic devices, traditional electronic accelerators can hardly meet the requirements of hardware computing power and energy consumption for large-scale computing operations. As an alternative, micro-ring resonator (MRR) and Mach-Zehnder interferometer (MZI)-based silicon photonic accelerators provide an effective solution to the problem faced by electronic accelerators. However, prior photonic accelerators need to read the weights from the external memory when performing the multiply-accumulate operation and mapping each value to the bias voltage of the MRR or MZI units, which increases the area and energy consumption. To solve the above problems, this paper proposes a nonvolatile silicon photonic convolutional neural network (NVSP-CNN) accelerator. This structure uses the Add-Drop MRR and nonvolatile phase change material Ge2Sb2Te5 (GST) to realize optical in-memory computing, which helps improve energy efficiency and computing density.MethodsFirstly, we design a photonic dot-product engine on the basis of GST and the Add-Drop MRR (Fig. 2). The GST is embedded on the top of the MRR, and its different crystallization degrees are used to change the refractive index of the MRR, which makes the output power of the Through and Drop ports change. The crystallization degree of GST is modulated outside the chip, and the light pulse increases the internal temperature of GST to change the crystallization degree. It is then cooled rapidly so that the crystallization state is preserved. This value remains unchanged for a long time without external current. During computational operations, a short and low-power optical pulse is injected from the MRR's input port and output from the Drop and Through ports. The output optical power is converted to electric power through a balanced photodiode, and Td-Tp is realized in the meantime. Therefore, the values of Td-Tp under different GST phase states can be used as the weight values in the neural network (Fig. 3). Then, we propose an optical matrix multiplier combined with wavelength division multiplexing (WDM) technology and the GST-MRR-based photonic dot-product engine (Fig. 4). Finally, the optical matrix multiplier is combined with the nonlinear parts (activation, pooling, and full connectivity) to build a complete accelerator, i.e., the NVSP-CNN accelerator (Fig. 5). In NVSP-CNN, the convolution operation is implemented optically, and the nonlinear part is realized electrically.ConclusionsThis paper proposes an MRR and GST-based photonic CNN accelerator structure for in-memory computing. Unlike the traditional MRR-based accelerator, the NVSP-CNN accelerator can avoid the power loss caused by the continuous external power supply for state maintenance and does not require external electrical pads for modulation. Hence, it can effectively reduce area loss. In addition, we implement the simulations on the MNIST and notMNIST datasets and achieve inference accuracies of 97.80% and 92.45%, respectively. Therefore, the proposed structure has advantages in power consumption, area loss, and recognition accuracy, which is expected to tackle most image recognition tasks in the future.
Acta Optica Sinica
- Publication Date: Feb. 25, 2023
- Vol. 43, Issue 4, 0415001 (2023)
A Calibration Method for Extrinsic Parameters of Monocular Laser Speckle Projection System
Zhuocan Jiang, Yueqiang Zhang, Biao Hu, Xiaolin Liu, and Qifeng Yu
Results and Discussions To verify the feasibility and accuracy of the proposed method, this paper establishes a monocular laser speckle projection system (Fig. 5). Firstly, the extrinsic parameters of the monocular laser speckle projection system are calibrated according to the aforementioned process. Then, the corresponding speckle points in the camera images are projected to the virtual imaging plane of the projector, and the offset error of corresponding points is calculated. The average offset errors mainly vary from 0.10 pixel to 0.18 pixel. The projection points of corresponding speckle points on the virtual imaging plane tend to be one point. The result shows that the calibration accuracy of the rotation matrix and the translation vector is high. Next, fourteen displacement experiments are further conducted in the range of 2-9 mm. The measured curve is basically consistent with the ideal curve (Fig. 7). The measurement errors of displacement are less than 0.16 mm. Furthermore, we conduct the 3D reconstruction experiment of standard spheres with known geometric parameters. The radius measurement errors of the two standard spheres are 0.0916 mm and 0.1274 mm, respectively. Their root-mean-square (RMS) errors are less than 0.1346 mm (Table 1). Finally, the ORBBEC's Astra-Pro is selected to demonstrate the depth measurement accuracy of the proposed method. Regardless of the average offset error or the depth distribution range, the plane reconstruction results of the proposed method are significantly better than those of Astra-Pro (Table 2). Simultaneously, the depth variation of the target model reconstructed by the method is smoother, and its density of point cloud is larger (Fig. 11). Hence, it can be easily concluded that the proposed method is able to calibrate the monocular laser speckle projection system effectively and achieve high-precision depth measurement.ObjectiveLaser speckle projection systems have been widely used in various fields, including but not limited to three-dimensional (3D) reconstruction, industrial detection, and gesture recognition. According to the number of infrared cameras, laser speckle projection systems are generally divided into two categories: the binocular mode and the monocular mode. A binocular laser speckle projection system consists of a laser speckle projector and two infrared cameras. The feature information provided by random speckle patterns is sufficient to match images in textureless areas, which significantly improves the accuracy and stability of binocular stereo vision systems. Moreover, speckle patterns in the infrared spectrum minimize the impact of the ambient light. However, the cost of binocular laser speckle projection systems is typically high, and the calibration process is complex. Compared with their binocular counterparts, monocular laser speckle projection systems are more compact and cost-effective. Due to the lack of reference speckle patterns, monocular laser speckle projection systems generally use a precise range finder to capture speckle images at different standard distances in advance. The measurement process is complex, and the deviation of the optical axis cannot be corrected online. To solve the aforementioned problems, this paper proposes a calibration method for the extrinsic parameters of monocular laser speckle projection systems. The virtual speckle image of the projector is generated by calculating the pose relationship between the infrared camera and the laser speckle projector. Only a calibration board with corner features is required in the proposed calibration process, rather than the precise range finder. With this method, a monocular laser speckle projection system becomes equivalent to a binocular stereo vision system with speckle images.MethodsFirst, a simple calibration board with corner features is designed. These features only occupy a small part of the calibration board, which leaves sufficient area for the speckle pattern. The plane equation of the calibration board in the camera coordinate system is calculated by extracting the coordinates of corner features in the image. Then, the laser speckle projector projects a random speckle pattern to the calibration board in different poses, and the infrared camera captures speckle images. Next, the digital image correlation (DIC) method is utilized to determine the corresponding speckle points in different speckle images. According to the plane equations of the calibration board, those speckle points are projected to corresponding planes, whose 3D coordinates can be obtained in the camera coordinate system. The straight lines fitted by corresponding speckle points pass through the center of the laser transmitter in the projector, which is regarded as the optical center of the projector. Therefore, the optical center and axis of the projector in the camera coordinate system are estimated by fitting corresponding lines. Finally, the pose relationship between the camera and the projector is solved and optimized. The virtual speckle image of the projector is generated by constructing the equation of planar homography. Through the aforementioned process, a monocular laser speckle projection system can be equivalent to a binocular stereo vision system with speckle images.ConclusionsIn this paper, a simple and efficient calibration method for the extrinsic parameters of monocular laser speckle projection systems is proposed. The 3D coordinates of the corresponding speckle points are calculated by adjusting the pose of the calibration board. Then, the relationship between the infrared camera and the laser speckle projector is solved and optimized to generate the virtual speckle image of the projector. The pose relationship of the monocular laser speckle projection system can be easily calibrated with the help of a calibration board with corner features, which improves calibration efficiency and reduces calibration costs. Generating the virtual speckle images of the projector enables the monocular laser speckle projection system to be equivalent to a binocular stereo vision system with speckle images, which significantly improves depth measurement accuracy. Simultaneously, the deviation of the optical axis can be corrected online. The experimental results show that the measurement errors of displacement and sphere radii are less than 0.16 mm and 0.13 mm, respectively. Within a certain depth range, the reconstruction results of the proposed method are significantly better than those of Astra-Pro. The proposed method can well improve the calibration efficiency and depth measurement accuracy of monocular laser speckle projection systems. Results and Discussions To verify the feasibility and accuracy of the proposed method, this paper establishes a monocular laser speckle projection system (Fig. 5). Firstly, the extrinsic parameters of the monocular laser speckle projection system are calibrated according to the aforementioned process. Then, the corresponding speckle points in the camera images are projected to the virtual imaging plane of the projector, and the offset error of corresponding points is calculated. The average offset errors mainly vary from 0.10 pixel to 0.18 pixel. The projection points of corresponding speckle points on the virtual imaging plane tend to be one point. The result shows that the calibration accuracy of the rotation matrix and the translation vector is high. Next, fourteen displacement experiments are further conducted in the range of 2-9 mm. The measured curve is basically consistent with the ideal curve (Fig. 7). The measurement errors of displacement are less than 0.16 mm. Furthermore, we conduct the 3D reconstruction experiment of standard spheres with known geometric parameters. The radius measurement errors of the two standard spheres are 0.0916 mm and 0.1274 mm, respectively. Their root-mean-square (RMS) errors are less than 0.1346 mm (Table 1). Finally, the ORBBEC's Astra-Pro is selected to demonstrate the depth measurement accuracy of the proposed method. Regardless of the average offset error or the depth distribution range, the plane reconstruction results of the proposed method are significantly better than those of Astra-Pro (Table 2). Simultaneously, the depth variation of the target model reconstructed by the method is smoother, and its density of point cloud is larger (Fig. 11). Hence, it can be easily concluded that the proposed method is able to calibrate the monocular laser speckle projection system effectively and achieve high-precision depth measurement.ObjectiveLaser speckle projection systems have been widely used in various fields, including but not limited to three-dimensional (3D) reconstruction, industrial detection, and gesture recognition. According to the number of infrared cameras, laser speckle projection systems are generally divided into two categories: the binocular mode and the monocular mode. A binocular laser speckle projection system consists of a laser speckle projector and two infrared cameras. The feature information provided by random speckle patterns is sufficient to match images in textureless areas, which significantly improves the accuracy and stability of binocular stereo vision systems. Moreover, speckle patterns in the infrared spectrum minimize the impact of the ambient light. However, the cost of binocular laser speckle projection systems is typically high, and the calibration process is complex. Compared with their binocular counterparts, monocular laser speckle projection systems are more compact and cost-effective. Due to the lack of reference speckle patterns, monocular laser speckle projection systems generally use a precise range finder to capture speckle images at different standard distances in advance. The measurement process is complex, and the deviation of the optical axis cannot be corrected online. To solve the aforementioned problems, this paper proposes a calibration method for the extrinsic parameters of monocular laser speckle projection systems. The virtual speckle image of the projector is generated by calculating the pose relationship between the infrared camera and the laser speckle projector. Only a calibration board with corner features is required in the proposed calibration process, rather than the precise range finder. With this method, a monocular laser speckle projection system becomes equivalent to a binocular stereo vision system with speckle images.MethodsFirst, a simple calibration board with corner features is designed. These features only occupy a small part of the calibration board, which leaves sufficient area for the speckle pattern. The plane equation of the calibration board in the camera coordinate system is calculated by extracting the coordinates of corner features in the image. Then, the laser speckle projector projects a random speckle pattern to the calibration board in different poses, and the infrared camera captures speckle images. Next, the digital image correlation (DIC) method is utilized to determine the corresponding speckle points in different speckle images. According to the plane equations of the calibration board, those speckle points are projected to corresponding planes, whose 3D coordinates can be obtained in the camera coordinate system. The straight lines fitted by corresponding speckle points pass through the center of the laser transmitter in the projector, which is regarded as the optical center of the projector. Therefore, the optical center and axis of the projector in the camera coordinate system are estimated by fitting corresponding lines. Finally, the pose relationship between the camera and the projector is solved and optimized. The virtual speckle image of the projector is generated by constructing the equation of planar homography. Through the aforementioned process, a monocular laser speckle projection system can be equivalent to a binocular stereo vision system with speckle images.ConclusionsIn this paper, a simple and efficient calibration method for the extrinsic parameters of monocular laser speckle projection systems is proposed. The 3D coordinates of the corresponding speckle points are calculated by adjusting the pose of the calibration board. Then, the relationship between the infrared camera and the laser speckle projector is solved and optimized to generate the virtual speckle image of the projector. The pose relationship of the monocular laser speckle projection system can be easily calibrated with the help of a calibration board with corner features, which improves calibration efficiency and reduces calibration costs. Generating the virtual speckle images of the projector enables the monocular laser speckle projection system to be equivalent to a binocular stereo vision system with speckle images, which significantly improves depth measurement accuracy. Simultaneously, the deviation of the optical axis can be corrected online. The experimental results show that the measurement errors of displacement and sphere radii are less than 0.16 mm and 0.13 mm, respectively. Within a certain depth range, the reconstruction results of the proposed method are significantly better than those of Astra-Pro. The proposed method can well improve the calibration efficiency and depth measurement accuracy of monocular laser speckle projection systems.
Acta Optica Sinica
- Publication Date: Feb. 10, 2023
- Vol. 43, Issue 3, 0315001 (2023)
Topics
© Copyright 2018-2021 | Chinese Laser Press. All Rights Reserved 沪ICP备15018463号-20